

Qwen3-TTS 1.7B核心功能与本地部署指南
作为目前开源领域的“性能卷王”,Qwen3-TTS(Text To Speech) 正式推出了1.7B参数版本的离线整合包。这款由Qwen团队开发的语音生成工具,不仅全面支持音色克隆、声线创造和高拟人化语音生成,更在多项实测指标中展现出碾压GPT-4o-Audio、ElevenLabs等商业旗舰产品的实力。对于追求数据隐私、需要低成本商用或离线环境运行的开发者来说,这无疑是目前的最佳开源TTS解决方案。
一、 核心技术亮点:重新定义开源语音合成
- 商业级拟人化表现
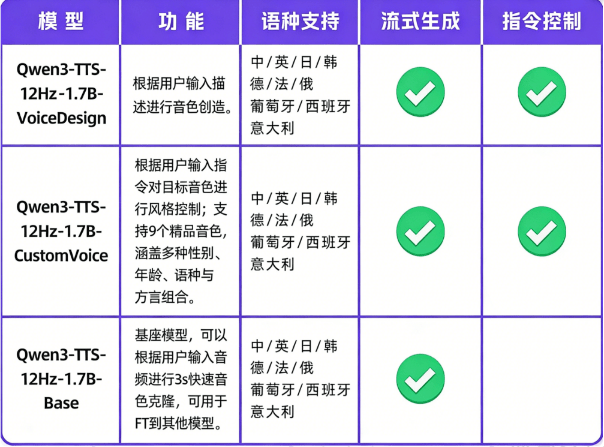
不同于传统TTS的“机器人念经”,Qwen3-TTS基于语义理解自适应调节语气、节奏与情感。无论是新闻播报还是情感对话,都能实现极高的自然度,真正将开源TTS的性能拉满至商业旗舰级。 - 3秒极速音色克隆(Few-Shot VC)
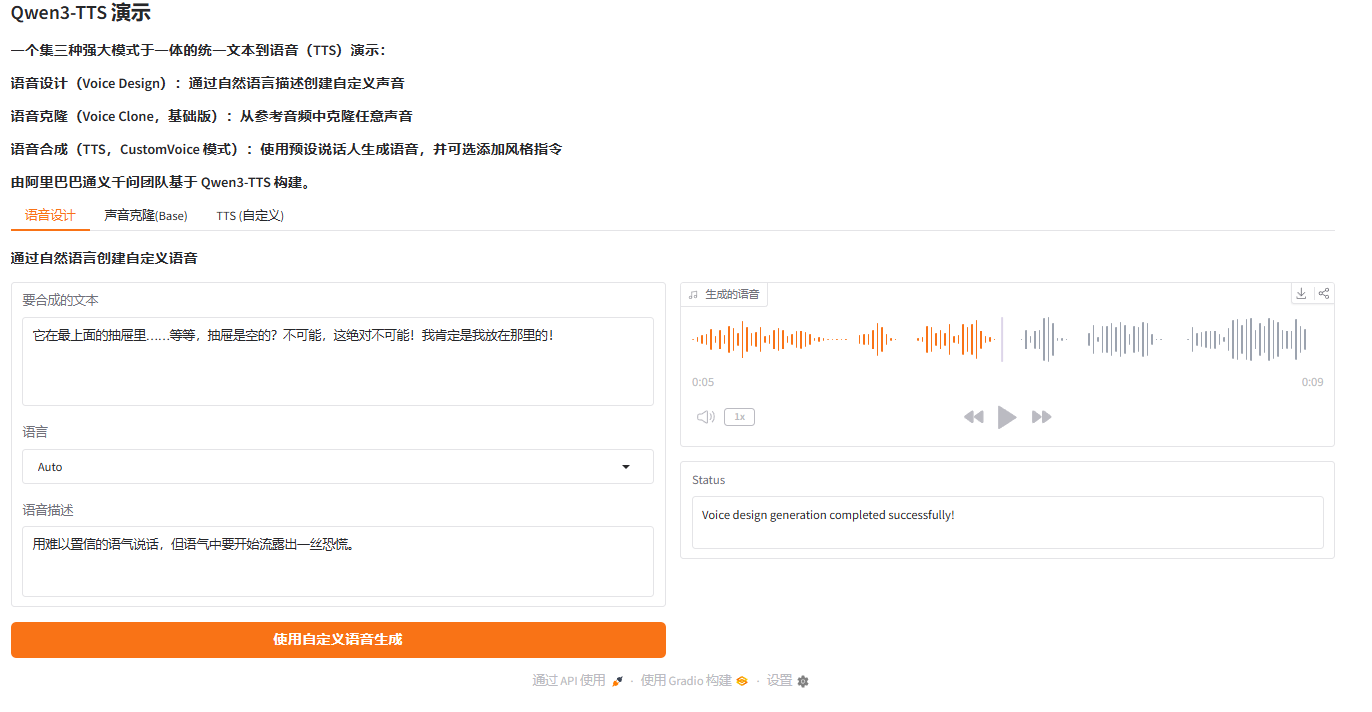
搭载Qwen3-TTS-VD-Flash模型,无需复杂的参数调试,仅需输入自然语言描述或极短的音频样本,即可定制专属声线。支持跨语种无缝切换,中文、英文、日韩语等主流语言一键生成。 - 完全离线与隐私安全
提供的离线整合包版本,断网也能运行。所有数据本地处理,彻底解决企业级用户对数据上传云端的隐私顾虑,且支持Windows系统一键解压即用。
二、 硬件配置与安装教程
为了让更多用户体验到顶尖AI语音技术,该模型对硬件要求极其友好:
- 显存需求: 最低仅需 4G显存 即可运行(推荐6G以上显存以获得更佳体验),甚至支持最新的50系显卡架构。
- 一键部署: 无需安装Python环境或复杂的依赖库,下载解压后双击启动程序即可使用。
- 常见问题解决: 若遇到解压报错,请务必使用 管理员身份运行WinRAR 进行解压,以确保文件权限完整。

总结
Qwen3-TTS 1.7B离线整合包是当前开源AI语音领域的“六边形战士”,凭借3秒极速克隆、情感语义自适应及极低的显存门槛(4G起),实现了对标GPT-4o-Audio的商业级效果。本次发布的一键整合包免去了繁琐的环境配置,支持完全离线运行,是AI视频配音、语音助手开发及个人创作者的必备神器。立即下载,体验零门槛的顶级AI语音生成!
会员全站资源免费获取,点击查看会员权益
普通用户可在下方单独购买课程!
隐藏内容
此处内容需要权限查看
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



